
一、历史
简介:R语言是用于统计分析、图形表示和报告的编程语言。1992年,由新西兰奥克兰大学统计学教授 Ross Ihaka 和 Robert Gentleman 设计开发。它是开源免费的,不同于stata、SPSS那些收费软件,不用担心盗版侵权的问题。
学习文档:https://bookdown.org/wangminjie/R4DS/(四川师范大学研究生公选课《数据科学中的R语言》,很详细)

二、环境配置
1.安装与配置
(1)第一步安装 R 。从官方网站 http://cran.r-project.org 免费下载。
(2)第二步安装 RStudio 。这是一个写代码的工具,从官方网站 https://posit.co/download/rstudio-desktop/ 下载,安装后会自动识别你前面安装的 R 版本 。
注意:
①软件的安装路径不要有中文和空格。
②旧版本的windows系统(如win7以下),可安装旧版本的Rstudio:https://rstudio.com/products/rstudio/older-versions/ 。
(3)第三步配置 RStudio 。
①宏包安装设置成国内镜像:Tools > Global options;
②防止R代码在不同设备间乱码,可以修改成 UTF-8 编码:Tools > Global options > Code > Saving > Default text encoding;
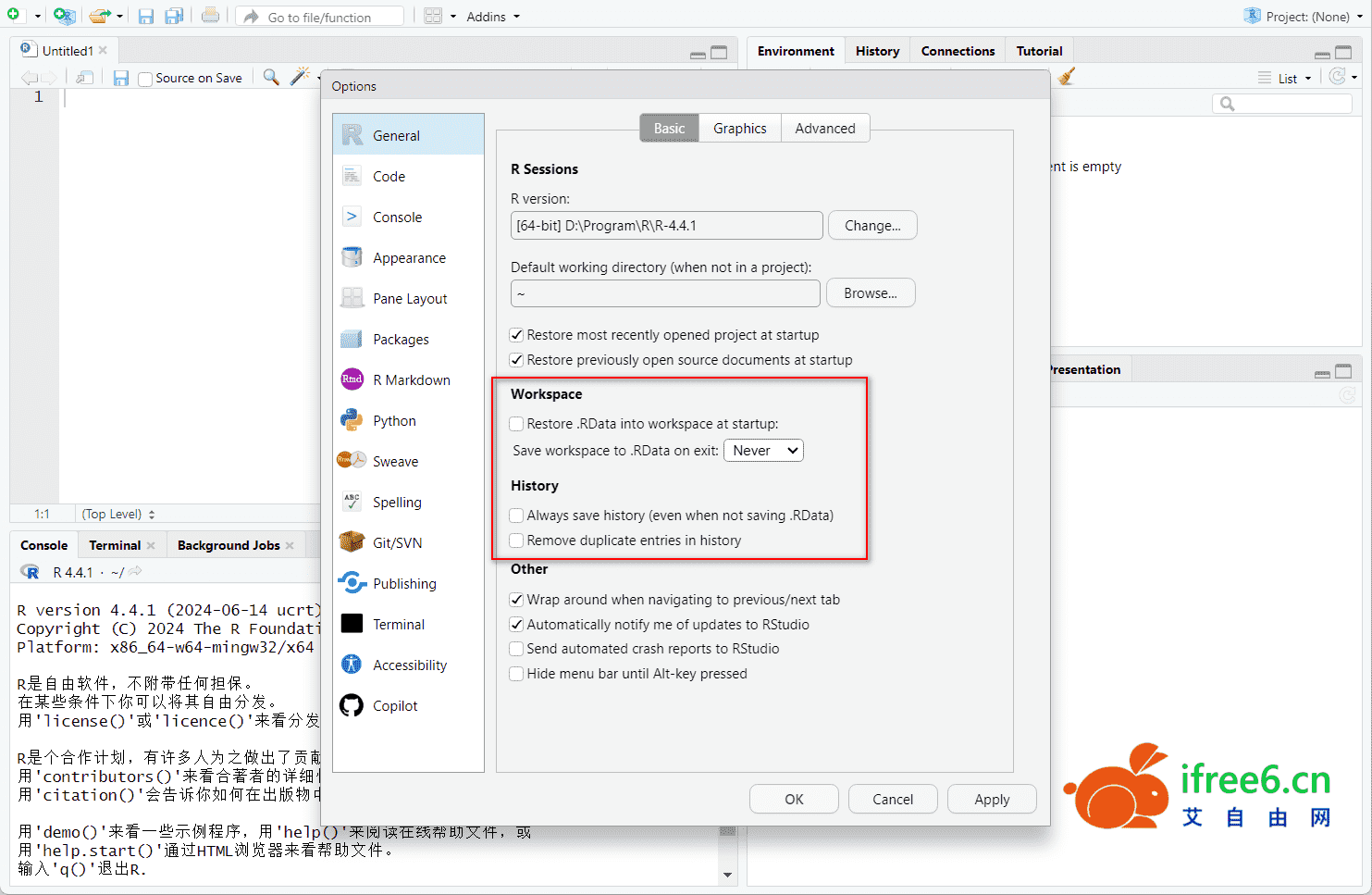
③如果每次打开 Rstudio 非常慢,可以将这几个选项取消掉(如下图):
(4)第四步安装宏包(简称“包”)。有两种方式,可以用代码命令安装(如下代码),也可用点击的方式安装(如下图)
# 安装单个包
install.packages("tidyverse")
# 安装多个包
install.packages(c("palmerpenguins", "patchwork", "gapminder", "ggridges", "readxl"))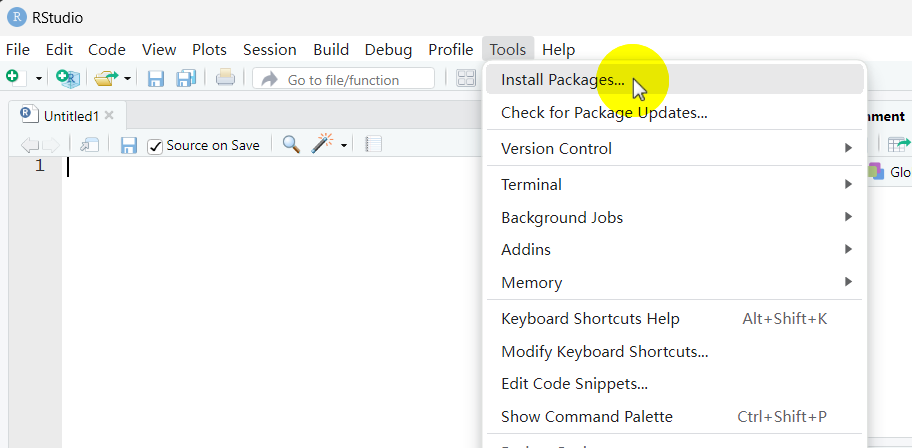
三、基本语法
1.注释
符号为 # 。作用在于:让阅读者更易理解代码,不会影响代码的执行。例如:
# 安装包
……
# 使用包
……
# 导入数据
……
2.快捷键
快捷键(Alt+Shift+K)非常好用,记住一些常用的快捷键,有事半功倍的效果。如果与其它软件冲突了,你也可以自定义快捷键。这里有一份中文说明:https://www.bilibili.com/opus/828582900315193447 。
①注释(comment):Ctrl+Shift+C(由于个人的习惯问题,我改成了“Ctrl+/”)
②查找和替换:Ctrl+F
③删除当前行:Ctrl+D
④移动当前行:Alt+上箭头/下箭头
3.对象
在R中存储的数据称为对象(object)。
(1)对象的创建与使用。下面的 x 就是一个对象,用于存储数字5。
# 赋值有两种方式,用“箭头”或者“等于号”(我喜欢后者,更简洁)
x <- 5
# 或者
x = 5(2)变量命名规则。变量名可以由字母、数字、下划线_和句点.组成,但只能以字母开头。长变量名,可以结合下划线命名,例如:school_name 。
(3)对象属性。最重要的两个属性是类型和长度,可用以下命令查看:
x = 666
typeof(x) # 查看对象的类型
length(x) # 查看对象的长度
4.向量
(1)向量类似于python中的数组,用 c() 函数表示,各元素之间用英文逗号隔开,是有顺序的。例如:
low = c(1, 2, 3)
high = c(4, 5, 6)
sequence = c(low, high)
sequence(2)向量也属于对象,因此有两个基本属性,即类型与长度。
(3)数值型向量,它的元素都是数值类型,有 integer (整数型)和 double(双精度型/小数) 两种。seq() 函数可以生成等差数列;rep() 函数可以产生重复出现的数字序列。
x = c(1L, 5L, 2L, 3L) # 整数型
x = c(1.5, -0.5, 2, 3) # 双精度类型,默认
x = c(3e+06, 1.23e2) # 双精度类型,科学计数法
s1 = seq(from = 0, to = 10, by = 0.5) # 生成一个从0到10,间隔0.5的数值型向量
s1
s2 = rep(x = c(0, 2), each = 2,times = 3 ) # 先重复x向量里面的元素2次,再整体重复3次
s2(4)字符串型向量,元素都是文本类型,用引号包含。
x = c("a", "b", "c")
y = c("hello", "I love you!")(5)布尔型向量,值为 TRUE 和 FALSE(必须全部大写,与Python不同)。题外话:几乎在所有的编程语言中,1等价于真,0等价于假。
x = c(TRUE, TRUE, FALSE, FALSE)
# 上面可简写(但不推荐)
x = c(T, T, F, F)(6)因子型向量,就是在“字符串型向量”的基础上增加了排序(也叫层级,levels)。
# 因子型向量
soldier = c("士兵", "营长", "军长") # 原始字符串型向量
soldier2 = factor(soldier,levels = c("军长", "营长", "士兵")) # 按职位从高到低显示
soldier2(7)强制转换。当一个向量中,同时存在“字符串、数字、布尔”三种类型的数据时,输出该向量,将强制转化成同一类型的数据。优先级,如下: 字符串 > 数字(小数 > 整数) > 布尔。
# 强制转换
qiang = c(12, "foo", TRUE)
print(qiang2) # 结果:"12" "foo" "TRUE"
qiang2 = c(12, 12.5, TRUE)
print(qiang2) # 结果:12.0 12.5 1.0
5.数据结构
数据结构包括向量、矩阵、列表、数据框。前面讲到的向量是最基础的,其它类型都由它衍生而来(都是它的子孙)。
(1)矩阵,可以存储行(row)和列(column)的二维数据,可以用 matrix() 函数创建。
# 假设我要将某个向量,变成2行3列的矩阵
m = matrix(
c(2, 4, 3, 1, 5, 7),
nrow = 2,
ncol = 3
)
m
# 结果:
# [,1] [,2] [,3]
# [1,] 2 3 5
# [2,] 4 1 7
# 总结:先竖着排,再横着排# 矩阵的3个属性:
class(m) # 类型(不是typeof)
length(m) # 长度
dim(m) # 维度(2)列表,它里面可以装各种类型的数据,比向量更强大,可以用 list() 函数创建列表。
list1 = list(
a = c(5, 10),
b = c("I", "love", "R", "language", "!"),
c = c(TRUE, TRUE, FALSE, TRUE)
)
list1# 列表有2个属性:
class(list1) #类型
length(list1) #长度(3)数据框,是一种特殊的列表,可以用 data.frame() 函数创建数据框,显示出来就像excel表格。
df = data.frame(
name = c("Alice", "Bob", "Carl", "Dave"),
age = c(23, 34, 23, 25),
marriage = c(TRUE, FALSE, TRUE, FALSE),
color = c("red", "blue", "orange", "purple")
)
df
# 结果:
# name age marriage color
# 1 Alice 23 TRUE red
# 2 Bob 34 FALSE blue
# 3 Carl 23 TRUE orange
# 4 Dave 25 FALSE purple
6.运算符及向量运算
(1)算术运算符,泛指加(+)、减(-)、乘(*)、除(/)、求余(%%)、求商(%/%)、点乘(内积,%*%)、指数(^)。点乘就是两个向量对应位置相乘后,再相加。
# 运算之前,我们先假装学习一下小学知识:
# A ÷ B = C …… D
# 上式中,A是被除数,B是除数,C是商,D是余。
# 两个向量相加(+)
a = c(1, 2, 3)
b = c(4, 5, 6)
a + b
# 结果:
# 5 7 9
# 两个向量求余(%%)
a = c(1, 2, 3)
b = c(4, 5, 6)
a %% b
# 结果:
# 1 2 3
# 两个向量相除求商(%/%)
a = c(1, 2, 3)
b = c(4, 5, 6)
a %/% b
# 结果:
# 0 0 0
# 两个向量的点乘(内积,%*%)
a = c(1, 2, 3)
b = c(4, 5, 6)
a %*% b
# 结果:
# 32(2)循环补齐。算术运算时,如果两个向量长度相等,就一一对应运算;如果长度不等时,短的那个向量会将里面的元素自动复制,来跟另一个向量长度保持一致,再运算。直接上例题:
x = c(1, 3)
y = c(10, 20, 30, 40)
x * y # 运算前会把x里面的元素复制成1,3,1,3,从而与第2个向量长度保持相同。
# 结果:
# 10 60 30 120
x = c(1, 3, 5)
y = c(10, 10, 10, 10)
x * y
# 结果:
# 10 30 50 10(3)关系运算符,就是比较两个向量( >, == , < , >= , <= , != , ! ),结果是一个布尔值(TRUE/FALSE)。
(4)冒号运算符( : ),可按顺序创建一个序列(一串数字),如:
# 创建一串从1到10的数字
a = 1:10
a
# 结果:
# 1 2 3 4 5 6 7 8 9 10(5)判断运算符( %in% ),可判断一个向量的元素,是否存在于另一个向量中,结果是布尔值。is.na() 函数可判断是否为缺失值(NA),NA的意思就是 not available 。
# 判断运算
c(2, 3, 7) %in% c(1, 2, 3, 4, 5)
# 结果:
# TRUE TRUE FALSE
is.na( c(1, 2, NA, 4) )
# 结果:
# FALSE FALSE TRUE FALSE(6)特殊值,主要指 Inf(表示无限大,-Inf 表示无限小), NaN(表示该数字无数学意义), NA(表示缺失) 和 NULL(表示没有值,空值)。
7.函数
(1)内置函数。
我们前面用过的向量操作符( c(x) )就是一个函数。此外,还有许多函数:打印( print(x) ),开方( sqrt(x) ),自然对数( log(x) ),求和( sum(x) ),求均值( mean(x) ),求标准差( sd(x) ),最小值( min(x) ),最大值( max(x) ),个数/长度( length(x) ),从小到大排序( sort(x) ),元素去重( unique(x) ),三元运算( ifelse(x > 5, "big", "small") ),是否为数值型( is.numeric(x) ),是否为字符串型( is.character(x) ),转化成字符串型( as.character(x) )。
(2)自己创建函数。当然,我们也可以自己构造一个函数,只需要写成下面这种格式就行:
# 自定义函数,求Z分数
my_std <- function(x) {
(x - mean(x)) / sd(x)
}
x = c(1, 5, 7, 8, 9, 3)
# 调用自定义函数
my_std(x)
# 结果:
# -1.4599928 -0.1622214 0.4866643 0.8111071 1.1355499 -0.8111071(3)安装宏与使用宏包,就是使用别人的函数大全,这个包里面通常用许多实用的函数,我们可以使用以下命令从官方下载(只要他存在)。
# 安装包的命令
install.packages("dplyr")
# 使用包的命令
library("dplyr")2.我应该下载哪个文件/软件? 答:通常“数字后缀”表示版本号(越大越新),下载数字最大的即可!
3.下载地址为什么隐藏了? 答:防止爬虫索引,敏感内容登录即可免费下载!





暂无评论内容